关注
联系我们
私信
订阅本站
主页
密圈资源
asmr专区
主播办卡asmr
同人声
国外asmr
名站写真
森萝财团
JKFUN
风之领域
喵写真
紧急企划
稚乖画册
cos福利合集
☎联系站长
站长
2021-05-11
5.09w
cos福利合集【持续更新】
PUA泡学课程全集【超1000G】
JK/死库水/白丝/黑丝/
主播私人定制asmr福利
抖音 奔跑的晶骡子 微密圈 NO.002期 【229P4V】
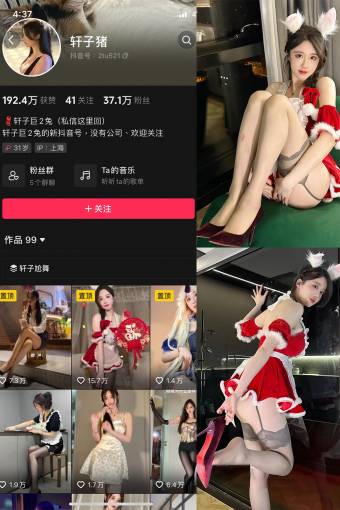
抖音 轩子巨二兔 微密圈 NO.004期 【21P3V】
抖音 轩子巨二兔 微密圈 NO.005期 【57P】
抖音 轩子巨二兔 微密圈 NO.003期 【41P4V】
抖音 奔跑的晶骡子 微密圈 NO.001期 【191P12V】
抖音 轩子巨二兔 微密圈 NO.001期 【39P2V】
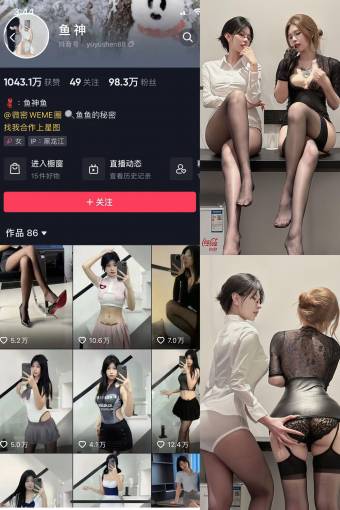
抖音 鱼神 微密圈 NO.053期 【30P】
抖音 小U优优子 VIP 微密圈 NO.026期 【6P1V】
查看更多
asmr专区
主播办卡asmr
同人声
国外asmr
真琴精选大熊Asmr福利视频,温柔哄睡助眠系
软糖小悦专业Asmr助眠视频11部合集
梵拉-valar姐姐会员限定Asmr福利视频5部合集,cos加甜耳法力无边
丸子君ASMR福利视频5部合集,制服黑丝甜耳魅惑
欧美女主播Diddly助眠ASMR视频精选
梵拉-valar助眠ASMR福利视频4部合集,cos加甜耳系列
轩子专业ASMR福利视频7部合集,绝美颜值的治愈哄睡
超萌萝莉4K!晓美专业ASMR福利视频5部合集
查看更多
JK正片
风之领域 0125 [40P]
风之领域 0124 [47P]
风之领域 0127 [39P]
风之领域 0126 [63P]
风之领域 0123 [39P]
风之领域 0115 [43P]
风之领域 0122 [45P]
风之领域 0117 [45P]
查看更多
cos福利合集
眼酱大魔王w 写真合集[90套] [持续更新]
雨波_HaneAme COS写真合集[372套][持续更新]
G44不会受伤 写真合集[104套][持续更新]
花铃 写真合集[41套][持续更新]
过期米线线喵 写真合集[154套][持续更新]
半半子 写真合集[66套][持续更新]
yuuhui玉汇 写真合集[52套][持续更新]
阿包也是兔娘 写真合集[92套][持续更新]
查看更多
×
登录
忘记密码 ?
登录
注册
注册登录即表示同意本站的用户协议和隐私政策




















![风之领域 0125 [40P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTVkZDgxYmM0NTg4NTNhZWY4Mjc1OTAuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0124 [47P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTVkZDc3NWM0NTg4NTNhZWY4MDg2YWIuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0127 [39P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTVkZDkwM2M0NTg4NTNhZWY4NWFiMzcuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0126 [63P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTVkZDg5N2M0NTg4NTNhZWY4NDAwNTguanBn&w=320&h=480&q=70&zc=1)
![风之领域 0123 [39P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTU3NDllM2M0NTg4NTNhZWY1MmNlYmIuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0115 [43P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTU3NDBkMGM0NTg4NTNhZWYzNDA5ZWIuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0122 [45P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTU3NDk2Y2M0NTg4NTNhZWY1MTNmMGEuanBn&w=320&h=480&q=70&zc=1)
![风之领域 0117 [45P]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTU3NDg0NGM0NTg4NTNhZWY0ZDI0OTcuanBn&w=320&h=480&q=70&zc=1)
![眼酱大魔王w 写真合集[90套] [持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGIxNjk0YzFkZGFjNTA3Y2NjNTBhODEuanBn&w=375&h=250&q=70&zc=1)
![雨波_HaneAme COS写真合集[372套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGIyYzU1ZTFkZGFjNTA3Y2NmNWQ2NTcuanBn&w=375&h=250&q=70&zc=1)
![G44不会受伤 写真合集[104套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGIzZGUzYzFkZGFjNTA3Y2MxYTViMjUuanBn&w=375&h=250&q=70&zc=1)
![花铃 写真合集[41套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGMzODIxYTFkZGFjNTA3Y2M0NWU0MDYuanBn&w=375&h=250&q=70&zc=1)
![过期米线线喵 写真合集[154套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGIyYzYxZjFkZGFjNTA3Y2NmOGM3MDQuanBn&w=375&h=250&q=70&zc=1)
![半半子 写真合集[66套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGIxNmFhMzFkZGFjNTA3Y2NjYTZlNTIuanBn&w=375&h=250&q=70&zc=1)
![yuuhui玉汇 写真合集[52套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NGMzN2M5YzFkZGFjNTA3Y2MzYjcxYzIuanBn&w=375&h=250&q=70&zc=1)
![阿包也是兔娘 写真合集[92套][持续更新]](https://www.hanapost.com/wp-content/themes/dragon/functions/timthumb.php?src=aHR0cHM6Ly9waWMuaW1nZGIuY24vaXRlbS82NTJlN2U0OGM0NTg4NTNhZWZhZjJmMmYucG5n&w=375&h=250&q=90&zc=1)